
利用网络爬虫主要目的是将呈现在网页上以非结构格式(html)存储的数据转化为结构化数据,在R中有诸如RCurl等包,rvest是比较常用的一个爬虫工具, 可以解决大部分的爬虫问题。
写一个简单的爬虫无需高深的网页知识,但是需要了解html的基本结构,一个典型的网页及代码如下(以豆瓣为例):

html是xml的一种,简单了解各个层级以及xpath的基本知识,可以通过(https://www.runoob.com/html/html-tutorial.html)进行简单学习即可。
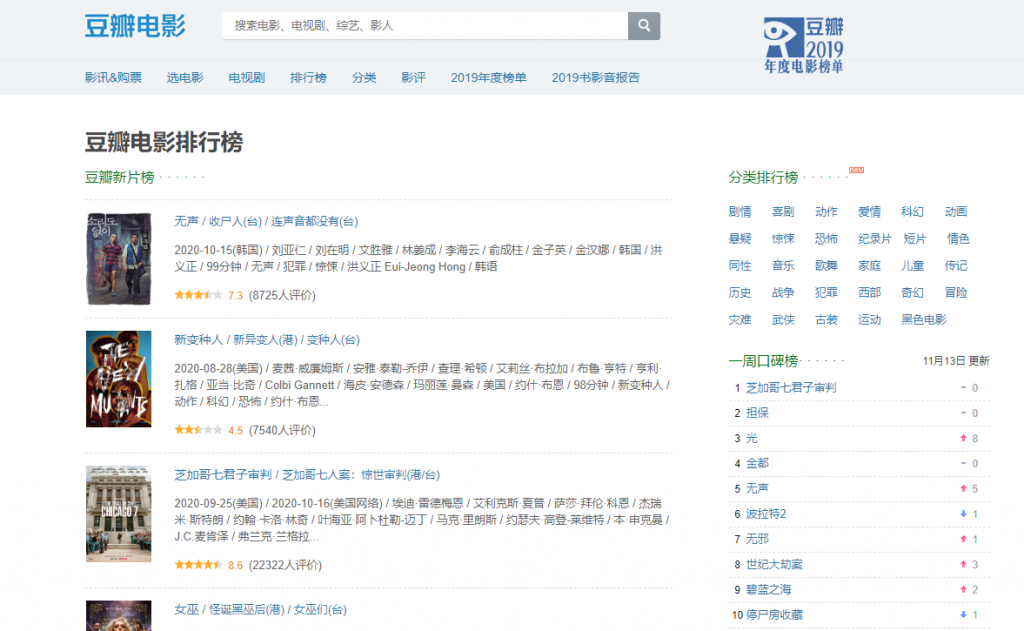
下面我们就用豆瓣的电影排行信息作为演示示例进行一个简单的爬虫演示:
1)首先观察网页结构:
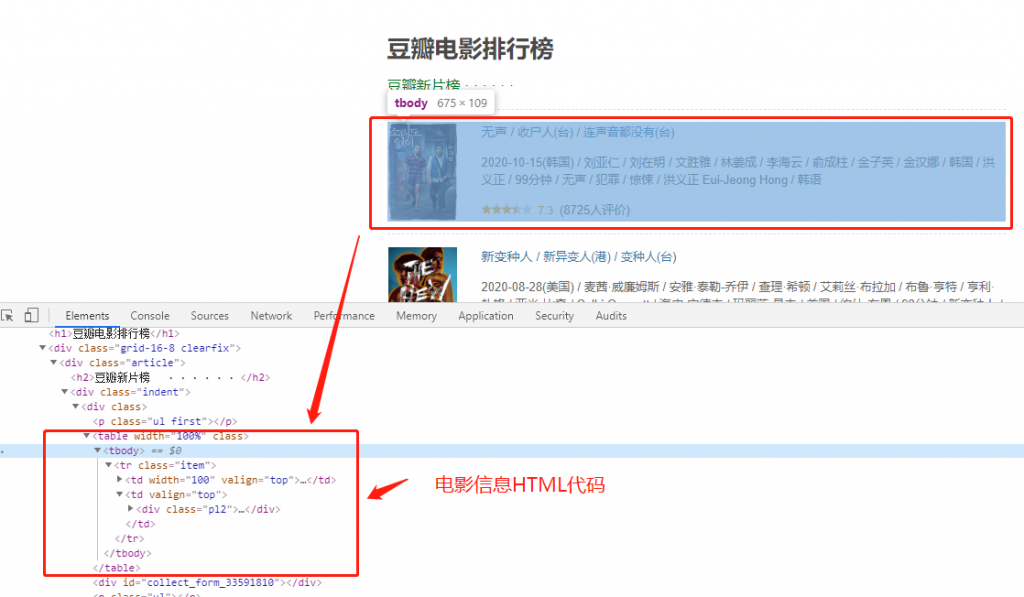
<table width="100%" class="">
<tbody><tr class="item">
<td width="100" valign="top">
<a class="nbg" href="https://movie.douban.com/subject/33591810/" title="无声">
<img src="https://img1.doubanio.com/view/photo/s_ratio_poster/public/p2620104689.webp" width="75" alt="无声" class="">
</a>
</td>
<td valign="top">
<div class="pl2">
<a href="https://movie.douban.com/subject/33591810/" class="">
无声
/ <span style="font-size:13px;">收尸人(台) / 连声音都没有(台)</span>
</a>
<p class="pl">2020-10-15(韩国) / 刘亚仁 / 刘在明 / 文胜雅 / 林姜成 / 李海云 / 俞成柱 / 金子英 / 金汉娜 / 韩国 / 洪义正 / 99分钟 / 无声 / 犯罪 / 惊悚 / 洪义正 Eui-Jeong Hong / 韩语</p>
<div class="star clearfix">
<span class="allstar35"></span>
<span class="rating_nums">7.3</span>
<span class="pl">(8725人评价)</span>
</div>
</div>
</td>
</tr>
</tbody></table>假设我们需要拿取电影名称、演员及关键词、评分信息,观察其结构,编写代码:
library(rvest)
# 豆瓣电影排行榜
url <- "https://movie.douban.com/chart"
# 用read_html函数读取网页信息
web <- read_html(url, encoding = "UTF-8")
# 片名
veido <- web %>% html_nodes("div.pl2 > a > span") %>% html_text()
# 演员
actor <- web %>% html_nodes("a.pl") %>% html_text()
# 评价
star <-
web %>% html_nodes("div.star > span.rating_nums") %>% html_text()
# 组合成数据框
Result <- data.frame(veido, actor, star)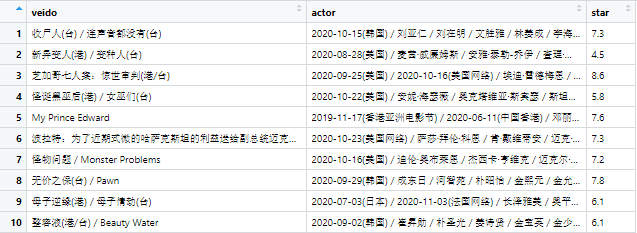
这样一个简单的爬虫就好了,对于日常简单采集数据信息的小伙伴是够用了
参考资料:
1.https://github.com/tidyverse/rvest
2.https://movie.douban.com/chart
