
mlxtend是一款基于python的机器学习扩展包,其本身使用非常简介方便自带数据集,同时也作为sklearn的一个补充和辅助工具。
它可以非常简单高效的利用堆栈泛化来构建更具预测性的模型,让我们能够快速组装堆叠回归器的库。集成了从数据到特征选择、建模(分类、聚类、图形图像,文本)、验证、可视化整个一套完整的workflow。
下面通过mlxtend演示我们常见的分类器的分类效果(此处主要用到scikit-learn和mlxtend):
# 安装:conda install scikit-learn
# scikit-learn 是基于 Python 语言的机器学习工具
from sklearn.datasets import make_classification
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.svm import SVC
from sklearn.naive_bayes import GaussianNB
from sklearn.neural_network import MLPClassifier
import matplotlib.pyplot as plt
# 安装:conda install -c conda-forge mlxtend
# mlxtend提供了多种分类和回归算法api,包括多层感知机、stacking分类器、逻辑回归等,
# 作为sklearn的一个补充和辅助工具
# https://github.com/rasbt/mlxtend
# 文档:https://rasbt.github.io/mlxtend/
from mlxtend.plotting import plot_decision_regions
import matplotlib.gridspec as gridspec
# 演示数据,此处也可以用mlxtend自带的数据集,其本身也集成了很多经典的数据集
X, y = make_classification(n_samples=200, n_features=2, n_informative=2, n_redundant=0, n_classes=2, random_state=1)
# 初始化分类器
clf1 = LogisticRegression(max_iter=1000)
clf2 = DecisionTreeClassifier()
clf3 = RandomForestClassifier()
clf4 = SVC(gamma='auto', max_iter=1000)
clf5 = GaussianNB()
clf6 = MLPClassifier(max_iter=1000)
# 定义画布
gs = gridspec.GridSpec(3, 2)
fig = plt.figure(figsize=(14,10))
# 第一标签
labels = ['Logistic Regression', 'Decision Tree', 'Random Forest', 'SVM', 'Naive Bayes', 'Neural Network']
for clf, lab, grd in zip([clf1, clf2, clf3, clf4, clf5, clf6],
labels,
[(0,0), (0,1), (1,0), (1,1), (2,0), (2,1)]):
clf.fit(X, y)
ax = plt.subplot(gs[grd[0], grd[1]])
# 利用mlxtend中plot_decision_regions函数,展示分类效果
fig = plot_decision_regions(X=X, y=y, clf=clf, legend=2)
plt.title(lab)
plt.show()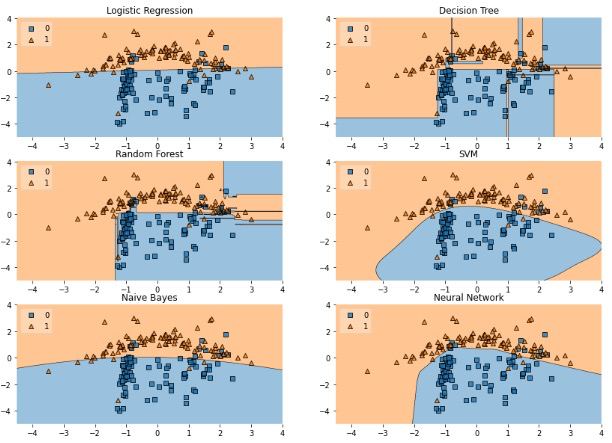
个人经验,在常见的高维度数据处理时使用单一的建模手段往往无法达到好的效果,可以尝试利用堆栈方法建立多级模型可能会有意想不到的效果。
参考资料:
1.https://python-bloggers.com/2020/09/decision-boundary-in-python/
2.https://rasbt.github.io/mlxtend/
3.https://github.com/rasbt/mlxtend
