
Slurm是一个开源(https://slurm.schedmd.com/),高度可扩展的集群管理工具和作业调度系统,用于各种规模的Linux集群。现在已经被全世界广泛运用:
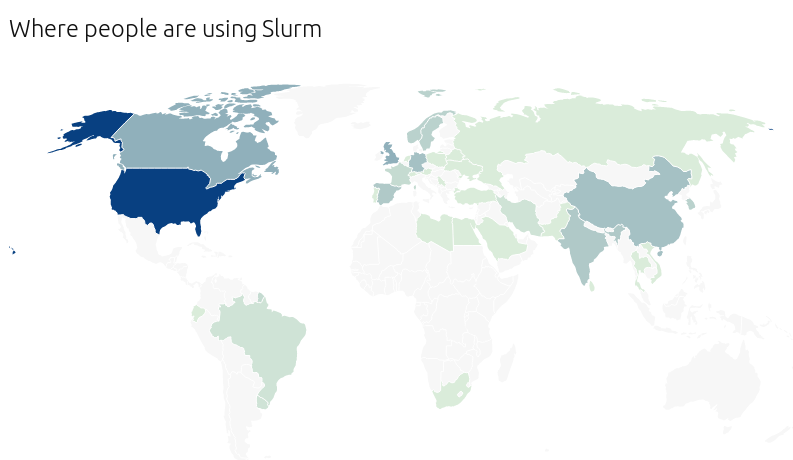
Slurm包含在每个计算节点上运行的slurmd守护程序和在管理节点上运行的中央slurmctld守护程序,用户可以很方便的提交任务到集群,易用性总体老说是较PBS好(个人使用经验,供参考)
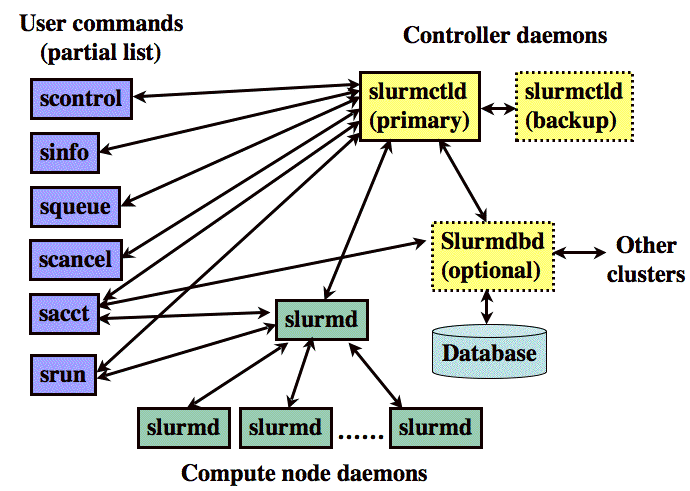
用户命令包括:sacct,salloc,sattach,sbatch,sbcast,scancel,scontrol, sinfo,smap,squeue,srun,strigger 和sview:
主要命令详细介绍如下:
sbatch用于提交作业脚本以供以后执行。该脚本通常包含一个或多个用于启动并行任务的srun命令。
scancel用于取消挂起或正在运行的作业或作业步骤。它还可用于向与正在运行的作业或作业步骤相关联的所有进程发送任意信号。
scontrol是用于查看和/或修改Slurm状态的管理工具。请注意,许多 scontrol 命令只能以root用户身份执行。
sinfo报告由Slurm管理的分区和节点的状态。它具有各种过滤,排序和格式选项。
smap报告由Slurm管理的作业,分区和节点的状态信息,但以图形方式显示反映网络拓扑的信息。
srun用于提交作业以便实时执行或启动作业步骤。 srun 有多种选项来指定资源要求,包括:最小和最大节点数,处理器数,要使用或不使用的特定节点,以及特定节点特征(如此多的内存,磁盘空间,某些必需的功能等) 。作业可以包含在作业节点分配中的独立或共享资源上顺序或并行执行的多个作业步骤。
1、Slurm部署安装(以单机安装为例,Ubuntu)
1)安装依赖和slurm包:
# 安装slurm,也可以https://slurm.schedmd.com下载源码,编译安装
sudo apt install slurm-wlm slurm-wlm-doc -y 2)安装完成后,首先需要配置/etc/slurm-llnl下的slurm.conf文件,以我的配置为例:
# 改成你的hostname
SlurmctldHost=evvail
MpiDefault=none
ProctrackType=proctrack/linuxproc
ReturnToService=1
SlurmctldPidFile=/var/run/slurmctld.pid
SlurmctldPort=6817
SlurmdPidFile=/var/run/slurmd.pid
SlurmdPort=6818
SlurmdSpoolDir=/var/spool/slurmd
SlurmUser=root
StateSaveLocation=/var/spool
SwitchType=switch/none
TaskPlugin=task/affinity
TaskPluginParam=Sched
InactiveLimit=0
KillWait=30
MinJobAge=300
#OverTimeLimit=0
SlurmctldTimeout=120
SlurmdTimeout=300
#UnkillableStepTimeout=60
#VSizeFactor=0
Waittime=0
#
#
# SCHEDULING
SchedulerType=sched/backfill
SelectType=select/cons_tres
SelectTypeParameters=CR_Core
# LOGGING AND ACCOUNTING
AccountingStorageType=accounting_storage/none
#AccountingStorageUser=
AccountingStoreJobComment=YES
ClusterName=cluster
JobCompType=jobcomp/none
#JobCompUser=
#JobContainerType=job_container/none
JobAcctGatherFrequency=30
JobAcctGatherType=jobacct_gather/none
SlurmctldDebug=info
#SlurmctldLogFile=
SlurmdDebug=info
# COMPUTE NODES
# 需要修改成你的服务器配置信息
NodeName=evvail NodeAddr=127.0.0.1 CPUs=2 State=UNKNOWN
PartitionName=control Nodes=evvail Default=YES MaxTime=INFINITE State=UP
PartitionName=computer Nodes=evvail Default=YES MaxTime=INFINITE State=UP
3)启动服务
systemctl start slurmctld
systemctld enable slurmctld
systemctl start slurmd
systemctl enable slurmd4)然后执行sinfo查看安装结果

5)用smap查看提交任务状态
2、常用命令导图

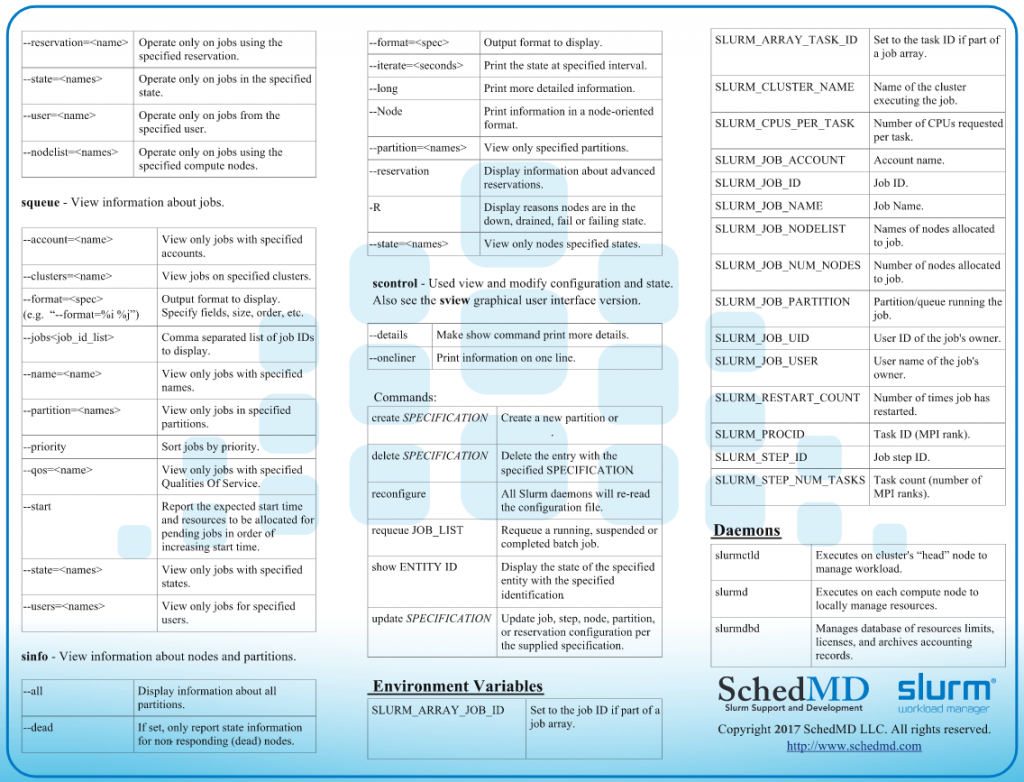
3、一个完整的Slurm模板
以conda环境切换的workflow为例,如下:
#!/bin/bash
#SBATCH -N 1 #节点数量
#SBATCH -J demo #作业名称
#SBATCH --cpus-per-task=1 #每个节点使用几个cpu核
#SBATCH -t 5:00 #执行时间
#SBATCH -o ~/Desktop/work/Slurm/ #输入路径
#SBATCH --output=%j.out #作业错误输出文件,%j代表作业ID
#SBATCH --error=%j.err #作业正确输出文件
#显示作业名称,作业ID,使用节点
echo -e "JOB NAME:$SLURM_JOB_NAME,Job ID:$SLURM_JOBID,Allocate Nodes:$SLURM_JOB_NODELIST"
sleep 15
#conda 环境
# >>> conda initialize >>>
# !! Contents within this block are managed by 'conda init' !!
__conda_setup="$('/home/chenhao/anaconda2/bin/conda' 'shell.bash' 'hook' 2> /dev/null)"
if [ $? -eq 0 ]; then
eval "$__conda_setup"
else
if [ -f "/home/chenhao/anaconda2/etc/profile.d/conda.sh" ]; then
. "/home/chenhao/anaconda2/etc/profile.d/conda.sh"
else
export PATH="/home/chenhao/anaconda2/bin:$PATH"
fi
fi
unset __conda_setup
# <<< conda initialize <<<
# 定义流程
pipeline1()
{
conda activate py36
which python >help.txt
}
pipeline2()
{
conda activate tf2
which python >>help.txt
}
pipeline3()
{
conda activate py3
which python >>help.txt
}
workflow()
{
pipeline1
pipeline2
pipeline3
}
# 执行工作流
workflow
sleep 15
用sbatch test.slurm提交任务,使用smap查看提交结果:
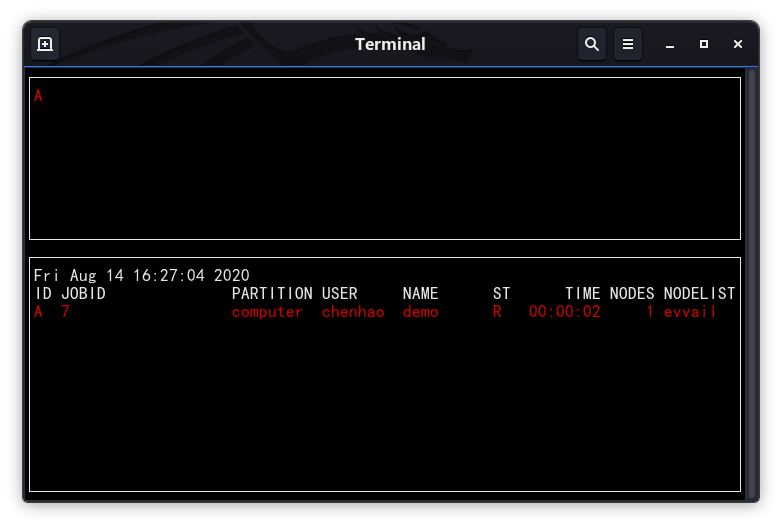
总体来说,安装和使用起来非常方便(PS:主要是安装比PBS方便太多)。
参考资料:
1.https://snapcraft.io/slurm
2.https://docs.slurm.cn/users/kuai-su-ru-men-yong-hu-zhi-nan
3.https://docs.hpc.sjtu.edu.cn/job/slurm/
4.http://hpc.pku.edu.cn/_book/guide/slurm/slurm.html
