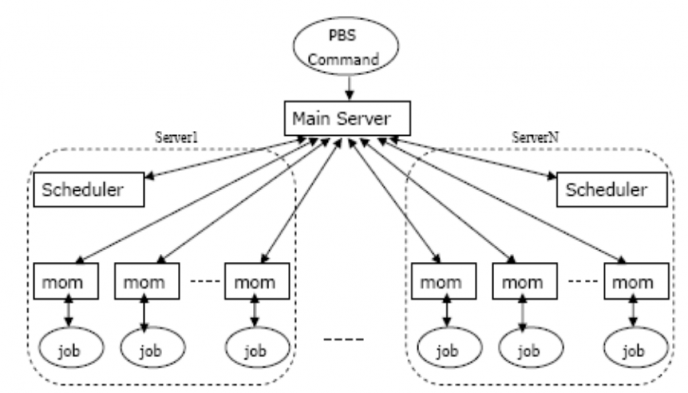
PBS(Portable Batch System)最初由NASA的Ames研究中心开发,主要为了提供一个能满足异构计算网络需要的软件包,用于灵活的批处理,特别是满足高性能计算的需要,如集群系统、超级计算机和大规模并行系统。
PBS的主要特点有:代码开放,免费获取;支持批处理、交互式作业和串行、多种并行作业,如MPI、PVM、HPF、MPL;PBS的目前包括openPBS, PBS Pro和Torque三个主要分支。 其中OpenPBS是最早的PBS系统,目前已经停止开发了; PBS pro是PBS的商业版本,功能颇为丰富; Torque是被商业公司维护openPBS的延伸版本,并给与后续支持的一个开源版本目前最新版6.1.3,也是目前使用最广泛的一个版本。
类似的作业调度系统如:Slurm、LSF等软件也是比较热门的集群调度系统,虽然每个系统命令差异不同,但是都大同小异。
本文以PBS介绍到提交一个完整的案例,全面介绍PBS的部署和使用,PBS主要由以下几部分构成:
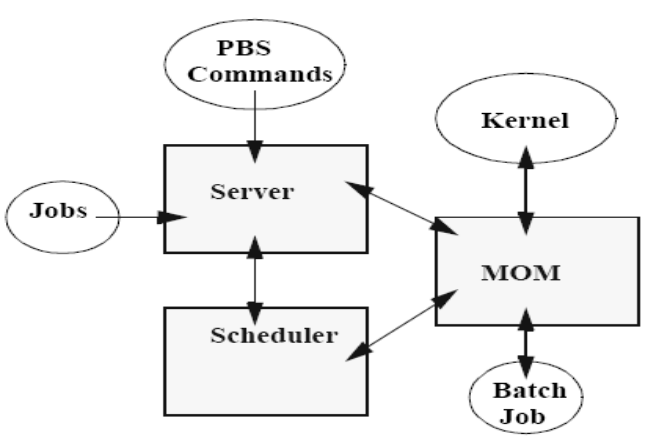
PBS command:用于用户提交、查看、修改和删除作业,管理节点提交命令。
Server:提供基本的批处理服务,例如接收/创建一个批处理作业,管理维护作业队列,管理输出结果等,安装在管理节点。
MOM:是一个守护进程,从Server处接收作业后放入其执行队列中等待执行,安装在计算节点。
Scheduler:对用户提交的作业进行调度,安装在管理节点。
1、部署与安装(以使用比较广泛的Torque-6.1.3和Centos7为例子)
1)首先可以去github上下载最新的Torque版本:https://github.com/adaptivecomputing/torque/tree/6.1.3
解压到目录
cd torque-6.1.32)安装软件依赖包
yum install libxml2-devel openssl-devel gcc gcc-c++ boost-devel libtool -y3)查看主机IP,修改主机hosts文件(/etc/hosts,如:我的主机名称是Evvail)
192.168.1.5 Evvail4)编译安装torque
./configure --with-default-server=$HOSTNAME
make & make install打包(如果需要多个计算节点部署),把产生的 packages: torque-package-clients-linux-x86-64.sh, torque-package-mom-linux-x86-64.sh 拷贝到所有计算节点上,安装即可(请确保安装前各个计算节点已经做好ssh互信,hosts文件已经添加相应的IP)。
./torque.setup <user> # 修改为你的用户名
make packages在计算节点上安装:
./torque-package-clients-linux-x86_64.sh --install
./torque-package-mom-linux-x86_64.sh --install安装完成后启动服务
for i in pbs_server pbs_sched pbs_mom ; do service $i restart; done5)添加系统服务,配置开机启动:
# 添加系统服务
cp contrib/init.d/{pbs_{server,sched,mom},trqauthd} /etc/init.d/
# 开启启动
chkconfig pbs_server on
chkconfig pbs_sched on
chkconfig pbs_mom on编辑/var/spool/torque/server_priv/nodes文件,添加节点信息:
evvail np=46)启动pbs_server,pbs_sched,pbs_mom,一般没有报错说明安装成功,报错大部分导致的原因是主机名和IP的配置原因,这个可以自行bing、谷歌搜索。
7)创建队列
执行qmgr,然后执行如下命令:
#
# Create and define queue long
#
create queue long
set queue long queue_type = Execution
set queue long Priority = 60
set queue long max_running = 10
set queue long resources_max.cput = 12:00:00
set queue long resources_min.cput = 02:00:01
set queue long resources_default.cput = 12:00:00
set queue long enabled = True
set queue long started = True
exit所有节点开启后执行qmgr -c "set server auto_node_np = True"
# 重启服务
for i in pbs_server pbs_sched pbs_mom trqauthd; do service $i restart; done
# 如果配置了防火墙,放行PBS使用端口
iptables -A INPUT -p tcp -m multiport --dports15001:15005 -j ACCEPT
iptables -A INPUT -p udp -m multiport --dports15001:15005 -j ACCEPT这里我们创建了一个名叫long的队列,部署方面到此告一段落,下面我们介绍基本的命令使用。
2、PBS基本命令使用
qsub:用来提交任务,qsub [ options ] [ command | -- [ command_args ]],执行后会返回一个任务号,表示提交成功,否则会返回错误信息
qsub [-a date_time] [-A account_string] [-c interval]
[-C directive_prefix] [-e path] [-f ] [-h ] [-I [-X]] [-j oe|eo] [-J X-Y[:Z]]
[-k keep] [-l resource_list] [-m mail_options] [-M user_list]
[-N jobname] [-o path] [-p priority] [-P project] [-q queue] [-r y|n]
[-R o|e|oe] [-S path] [-u user_list] [-W otherattributes=value…]
[-S path] [-u user_list] [-W otherattributes=value…]
[-v variable_list] [-V ] [-z] [script | — command [arg1 …]]
qsub –version
qstat:命令格式是qstat[-f][ -a][-i] [- n][-s] [-R] [-Q][-q][-B][ -u],显示自己提交的任务列表;
qstat [-f] [-J] [-p] [-t] [-x] [-E] [-F format | -w] [-D delim] [ job_identifier… | destination… ]
qstat [-a|-i|-r|-H|-T] [-J] [-t] [-u user] [-n] [-s] [-G|-M] [-1] [-w]
[ job_identifier… | destination… ]
qstat -Q [-f] [-F format] [-D delim] [ destination… ]
qstat -q [-G|-M] [ destination… ]
qstat -B [-f] [-F format] [-D delim] [ server_name… ]
qstat –version
参数说明:
-f jobid列出指定作业的信息
-a 列出系统所有作业
-i 列出不在运行的作业
-n 列出分配给此作业的结点
-s 列出队列管理员与scheduler所提供的建议
-R 列出磁盘预留信息
-Q 操作符是destination id,指明请求的是队列状态
-q 列出队列状态,并以alternative形式显示
-au userid列出指定用户的所有作业
-B 列出PBS Server信息
-r 列出所有正在运行的作业
-Qf queue 列出指定队列的信息
-u 若操作符为作业号,则列出其状态。
qdel:终止任务,例如qdel 123456,即为终止123456号任务,每个用户也只能终止自己提交的任务;
qdel [-W force|suppress_email=X] [-x] job_identifier…
qdel –version
参数说明:
qdel [-W 间隔时间] 作业号
PBS脚本:
PBS作业脚本选项(若无-C选项,则每项前面加’#PBS’)
-a date_timedate_time格式为:[[[[CC]YY]MM]DD]hhmm[.SS]表示经过date_time时间后作业才可以运行。
-c interval定义作业的检查点间隔,如果机器不支持检查点,则忽略此选项。
-C directive_prefix在脚本文件中以directive_prefix开头的行解释为qsub的命令选项。若无此选项,则默认为’#PBS’
-e path将标准错误信息重定向到path
-I 以交互方式运行
-j join将标准输出信息不标准错误信息合并到一个文件join中
-k keep定义在执行结点上保留标准输出和标准错误信息中的哪个文件。keep为o表示保留前者,e表示后者,oe或eo表示二者都保留,n表示皆不保留。若忽略此选项,二者都不保留。
-l resource_list定义资源列表,几个常用的资源种类:cput=N请求N秒的CPU时间,也可以是hh:mm:ss的形式。mem=N[K|M|G][B|W] 请求N {k|m|g}{bytes|words}大小的内存。nodes=N:ppn=M请求N个结点,每个结点M个处理器。
-m mail_optionmail_option为a:作业abort时给用户发信为b:作业开始运行发信为e:作业结束运行时发信,若无此选项,默认为a
-M user_list定义有关此作业的mail发给哪些用户
-N name作业名,限15个字符,首字符为字母,无空格
-o path重定向标准输出到path
-p priority任务优先级,整数,[-1024,1023],若无定义则为0
-q destinationdestination有三种形式:queue;@server;queue@server-r y|n表明作业是否可运行,y为可运行,n为不可运行
-S shell表明执行运行脚本所用的shell,须包含全路径。
-u user_list定义作业将在运行结点上以哪个用户名来运行。
-v variable_list定义export到本作业的环境变量的扩展列表。
-V表明qsub命令的所有环境变量都export到此作业。
-W additional_attributes作业的其它属性-z挃明qsub命令提交作业后,不在终端显示作业号。
3、一个完整的PBS模板
#!/bin/bash
# PBS模板
# 作者:Evvail.com
# 时间:2020
#
#
# 指定环境为当前提交环境
#
#PBS -V
#
# 指定任务名称
#
#PBS -N test
#
# 定义标准输出
#
#PBS -o out.log
#PBS -e err.log
#
# 定义提交到的任务队列名称
#
#PBS -q long
#
# 定义使用的终端
#
#PBS -S /bin/bash
#
# 定义所需要的资源
#
#PBS -l mem=512mb
#PBS -l nodes=1:ppn=2
#
# 输出提交队列基本信息
#
echo ------------------------------------------------------
echo -n 'Job is running on node '; cat $PBS_NODEFILE
echo ------------------------------------------------------
echo PBS: qsub is running on $PBS_O_HOST
echo PBS: originating queue is $PBS_O_QUEUE
echo PBS: executing queue is $PBS_QUEUE
echo PBS: working directory is $PBS_O_WORKDIR
echo PBS: execution mode is $PBS_ENVIRONMENT
echo PBS: job identifier is $PBS_JOBID
echo PBS: job name is $PBS_JOBNAME
echo PBS: node file is $PBS_NODEFILE
echo PBS: current home directory is $PBS_O_HOME
echo PBS: PATH = $PBS_O_PATH
echo ------------------------------------------------------
#
# 定义环境
#
SERVER=$PBS_O_HOST
WORKDIR=~/Desktop/work/PBS/
# 加载conda环境
#
# conda.sh
#
# # >>> conda init >>>
# # !! Contents within this block are managed by 'conda init' !!
# __conda_setup="$(CONDA_REPORT_ERRORS=false '/home/anaconda2/bin/conda' shell.bash hook 2> /dev/null)"
# if [ $? -eq 0 ]; then
# \eval "$__conda_setup"
# else
# if [ -f "/home/anaconda2/etc/profile.d/conda.sh" ]; then
# . "/home/anaconda2/etc/profile.d/conda.sh"
# CONDA_CHANGEPS1=false conda activate base
# else
# \export PATH="/home/anaconda2/bin:$PATH"
# fi
# fi
# unset __conda_setup
# # <<< conda init <<<
#
#
source $WORKDIR/conda.sh
# 创建工作目录
cd $WORKDIR
mkdir PBS_$PBS_JOBID
cd $WORKDIR/PBS_$PBS_JOBID
# 定义流程
pipeline1()
{
conda activate py36
which python >help.txt
}
pipeline2()
{
conda activate tf2
which python >>help.txt
}
pipeline3()
{
conda activate py3
which python >>help.txt
}
workflow()
{
pipeline1
pipeline2
pipeline3
}
# 执行工作流
workflow
# 结束
exit
以上内容均为本人总结和整理,部分内容来源PPT或者torque官方教程。
参考资料:
1.https://github.com/adaptivecomputing/torque/tree/6.1.3
