在机器学习领域中,混淆矩阵(confusion matrix)是一种评价模型结果的优劣的指标。
以分类模型中的二分类为例,我们会得到模型中那些是正样本那些是负样本,其中那些正样本可以正确识别或者是被错误的识别为负样本,反之亦然,这样我们会得到一个对正负样本判断的矩阵( confusion matrix ),称之为混淆矩阵:
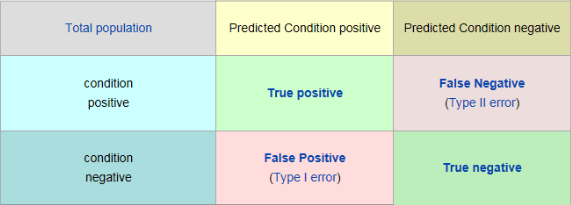
如此就得到了四个基础指标:
TP:True Positive,样本的真实类别是正类,并且模型预测的结果也是正类
FN:False Negative,样本的真实类别是正类,但是模型将其预测成为负类
FP:False Positive,样本的真实类别是负类,但是模型将其预测成为正类
TN:True Negative,样本的真实类别是负类,并且模型将其预测成为负类
但是我们实际在应用中很少直接用上面四个基础指标来评价模型的好坏。一般来说,我们是希望TP+TN是越大越好,所以在实际的应用中又通过以上四个基础的指标衍生出以下指标:

计算公式及详细信息如下:
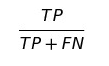
TPR(True positive rate),也称灵敏度(Sensitivity)或者召回率(Recall)
TNR(True negative rate),也称特异度(Specificity)
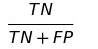
PPV(Positive predictive value),也称精确率(Precision)

NPV(Negative predictive value)
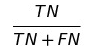
FNR(False negative rate)
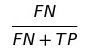
FPR(False positive rate)
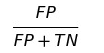
FDR(False discovery rate)
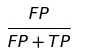
FOR(False omission rate)
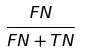
TS(Threat Score)
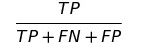
PT(Prevalence Threshold)

STP( Statistical Parity )
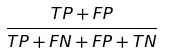
BA(Balanced Accuracy)
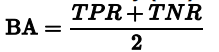
ACC(Accuracy),准确率,也是机器学习中常用的指标之一
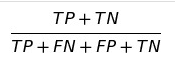
F1(F1 Score),F1-Score结合了Precision与Recall的结果。F1-Score的取值范围0~1,1代表模型的输出较好,0代表模型的输出结果较差

FM(Fowlkes–Mallows index)

BM(informedness or bookmaker informedness)

MK(markedness or deltaP)
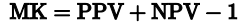
MCC(Matthews correlation coefficient),马修斯相关系数,考虑了真阳性、真阴性和假阳性和假阴性,通常认为该指标是一个比较均衡的指标,描述实际分类与预测分类之间的相关系数,它的取值范围为-1~1,取值为1时表示对完美预测,取值为0时表示预测的结果较差,-1是指预测分类和实际分类完全不一致

ROC(Receiver Operating Characteristic),是以FPR为横轴,TPR为纵轴绘制的测试曲线
AUC(Area Under Curve),ROC曲线下方的面积
国内访问wiki困难,以下是wiki的详细解释:
参考资料:
1.https://en.wikipedia.org/wiki/Confusion_matrix
2.https://modeloriented.github.io/fairmodels/
