
PyCaret是基于python的一个机器学习工具套件(和R包Caret类似)集合了多种机器学习方法。从数据预处理、建模再到最后的模型预处理几乎实现0代码,是数据分析人员(狭义的调参侠)的福音。PyCaret集合了像sklearn、xgboost、catboost等优秀的机器学习的包,功能覆盖了像数据的预处理(缺失值、异常值等)、模型的训练、模型集成和分析、模型的测试对比等功能。

涵盖了主流的所有场景的应用。
# 最新版2.0安装,由于安装依赖包较多建议用国内源
pip instll -i https://pypi.doban.com/simple pycaret==2.0PyCaret本身自带了约60个左右常用的数据集:
from pycaret.datasets import get_data
index = get_data('index')
可以在github上下载这些数据集,这也是很好的学习材料。下面介绍一下PyCaret包含了那些模型,按照不同任务分类(注:部分方法可用于多种任务可能会重复出现):
1)分类任务(Classification)
from pycaret.classification import *
models()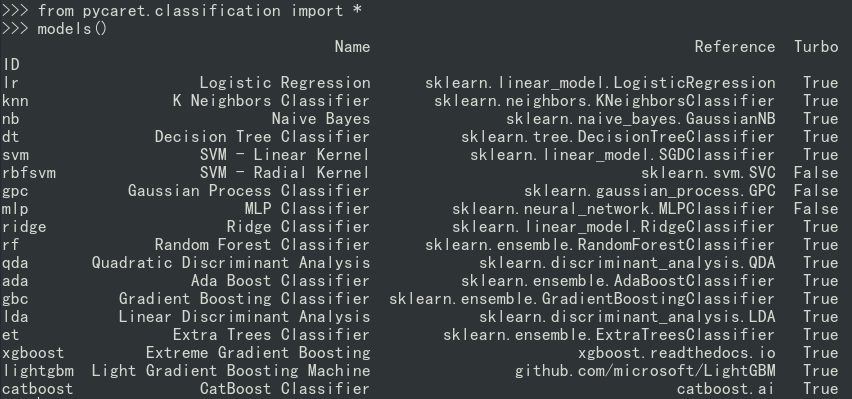
2)回归任务(Regression)
from pycaret.regression import *
models()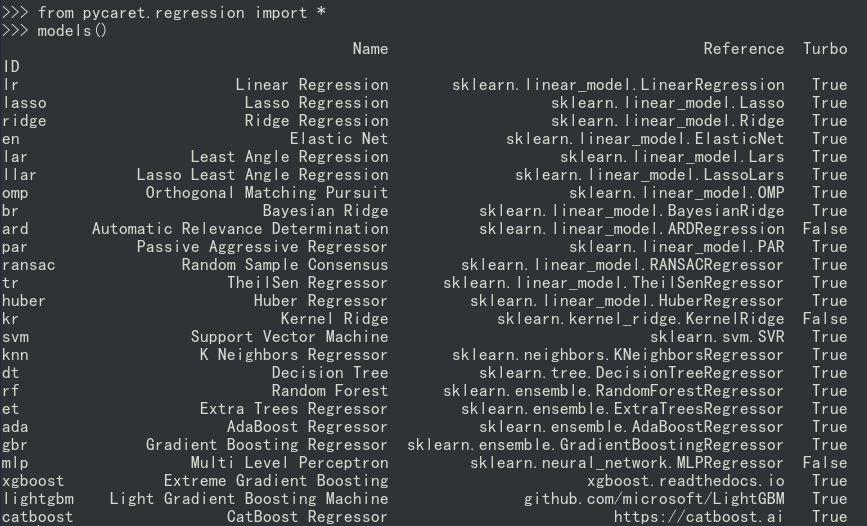
3)聚类任务(Clustering)
from pycaret.clustering import *
models()
4)异常检测(Anomaly Detection)
from pycaret.anomaly import *
models()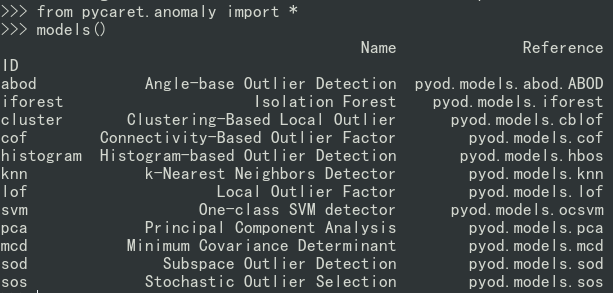
5)自然语言处理(NLP)
from pycaret.nlp import *
models()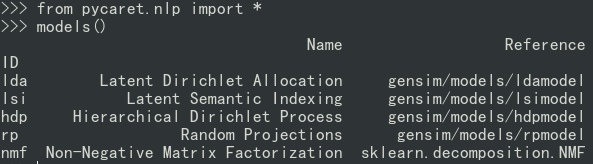
主要包含以上5种机器学习任务,可以看到PyCaret作为一个工具套件已经包含了主流的ML算法。
参考资料:
1.https://pycaret.org/guide/
