Scikit-learn是一个专门面向机器学习的工具包,Scikit-learn的基本功能主要被分为六大部分:分类,回归,聚类,数据降维,模型选择和数据预处理。
支持向量机(SVM)也是经典算法的一种,本次我们用Scikit-learn展示SVM在分类方面的应用。
SVM优势在于:
- 在高维空间中非常高效
- 即使在数据维度比样本数量大的情况下仍然有效
- 在决策函数(称为支持向量)中使用训练集的子集,因此它也是高效利用内存的
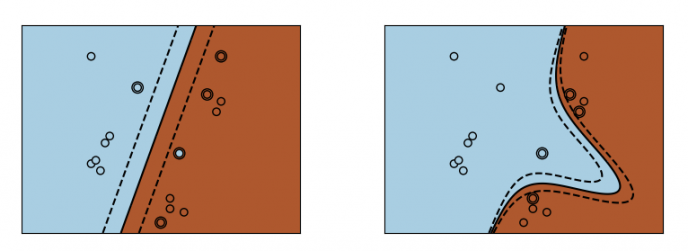
- 通用性: 不同的核函数 核函数 与特定的决策函数
SVM缺点包括:
- 如果特征数量比样本数量大得多,在选择核函数时要避免过拟合, 而且正则化项是非常重要的
- 支持向量机不直接提供概率估计,这些都是使用交叉验证计算等
我们用iris数据集做演示:
# -*- coding: utf-8 -*-
from sklearn import datasets
from sklearn import svm
import numpy as np
import matplotlib.pyplot as plt
if __name__ == '__main__':
# 获取数据
iris = datasets.load_iris()
x = iris.get('data')[:, 2:]
y = iris.get('target')
# 随机划分训练集和测试集
num = x.shape[0]
# 划分比例,训练集数目:测试集数目
ratio = 7 / 3
# 测试集样本数目
num_test = int(num / (1 + ratio))
# 训练集样本数目
num_train = num - num_test
index = np.arange(num)
# 固定随机种子
np.random.seed(0)
np.random.shuffle(index)
# 获取训练集数据
x_train = x[index[num_test:], :]
y_train = y[index[num_test:]]
# 获取测试集数据
x_test = x[index[:num_test], :]
y_test = y[index[:num_test]]
# 测试不同核函数模型
for kernel in ('linear', 'poly', 'rbf'):
# 建模
# 'ovo'时,为one v one分类问题,即将类别两两之间进行划分,用二分类的方法模拟多分类的结果
# 'ovr'时,为one v rest分类问题,即一个类别与其他类别进行划分。
clf = svm.SVC(decision_function_shape="ovr",
# 核函数
kernel=kernel,
# gamma值越小,分类界面越连续;gamma值越大,分类界面越“散”,分类效果越好,但有可能会过拟合
gamma=3,
# kernel='linear'时,为线性核函数,C越大分类效果越好,但有可能会过拟合(defaul C=1)
C=2)
clf.fit(x_train, y_train)
# 输出准确率
print("%s kernel: Train dataset accuracy is %.4f" % (kernel, clf.score(x_train,y_train)))
# 绘图
# 确定坐标轴范围
x_min, x_max = x_train[:, 0].min() - 1, x_train[:, 0].max() + 1
y_min, y_max = x_train[:, 1].min() - 1, x_train[:, 1].max() + 1
# 生成网格采样点
XX, YY = np.meshgrid(np.arange(x_min, x_max, .01),
np.arange(y_min, y_max, .01))
# 预测分类值
Z = clf.predict(np.c_[XX.ravel(), YY.ravel()])
Z = Z.reshape(XX.shape)
plt.pcolormesh(XX, YY, Z, cmap=plt.cm.Paired)
plt.scatter(x_train[:, 0],
x_train[:, 1],
c=y_train,
zorder=10,
cmap=plt.cm.Paired,
edgecolors='k')
plt.title('kernel: %s' % kernel)
# 计算测试集分类准确率
print("%s kernel: Test dataset accuracy is %.4f" % (kernel, clf.score(x_test,y_test)))
plt.show()
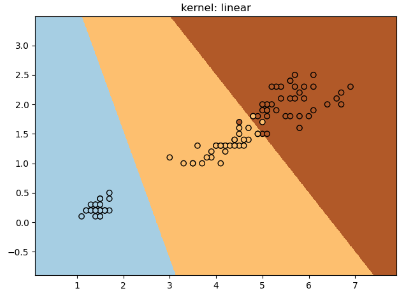
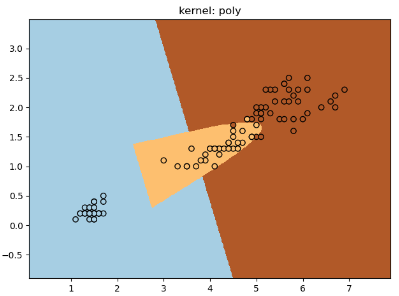
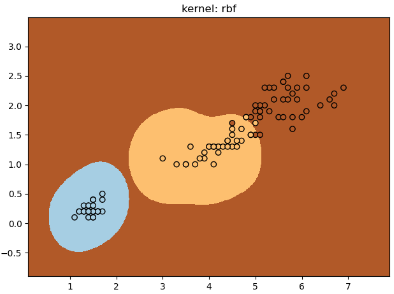
大家也可以参考官方演示文档:https://scikit-learn.org/stable/auto_examples/svm/plot_iris_svc.html
参考资料:
1.https://scikit-learn.org/stable/modules/svm.html
2.https://scikit-learn.org/stable/auto_examples/svm/plot_svm_kernels.html#sphx-glr-auto-examples-svm-plot-svm-kernels-py
3.https://scikit-learn.org/stable/index.html
