e1071包非常丰富,其实现了机器学习里面的SVM(支持向量机)算法,NB(朴素贝叶斯)算法、模糊聚类算法、装袋聚类算法等。本次我们它来做支持向量机模型预测。
支持向量机原理简介:支持向量机构建了一个超平面,使得高维特征空间内两个类的边缘间隔最大,定义超平面的向量就被称为支持向量。 SVM的优势就在于利用了面向工程问题的核函数( e1071 包提供了四种核函数:linear/polynomial/radial/sigmoid),能够提供准确率非常高的分类模型,同时借助增则向可以避免模型的过度适应,用户也不用担心诸如局部最优和多重共线性难题。
下面我们用 e1071 包让大家对SVM模型优化有一个简单的了解:
library(e1071)
# 准备数据
data(iris)
attach(iris)
set.seed(2020)
# 划分训练集、测试集
index <- sample(1:nrow(iris), 105, replace = F)
train_data <- iris[index,]
test_data <- iris[-index,]
# 调参
tune.model <-
tune.svm(
Species ~ .,
kernel="polynomial",
type = "C",
degree = c(2:10),
data = train_data,
gamma = 10 ^ (-6:1),
cost = c(1:100)
)
# 查看参数
summary(tune.model)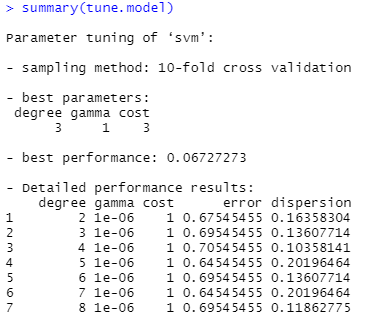
# svm建模
model <- svm(Species ~ .,
data = train_data,
# 核函数包含:linear/polynomial/radial/sigmoid
kernel = "polynomial",
# 用于除线性核函数之外的所有核函数参数,默认为1
gamma = tune.model$best.parameters$gamma,
degree = tune.model$best.parameters$degree,
cost = tune.model$best.parameters$cost,
# 分类:C-classification(default)/nu-classification
# 文本分类:one-classification
# 回归:eps-regression(default)/nu-regression
type = "C",
# 交叉验证
cross = 5)
print(model)
summary(model)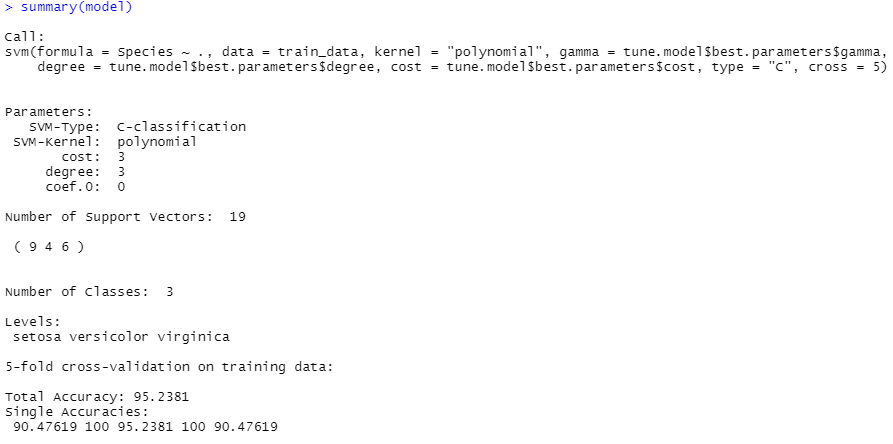
总体来说准确率95.23%,还算不错,下面查看建模效果:
# 训练集测试
pred <- predict(model, train_data)
# 生成混淆矩阵
table(pred, train_data$Species)
# slice,请查看plot.svm
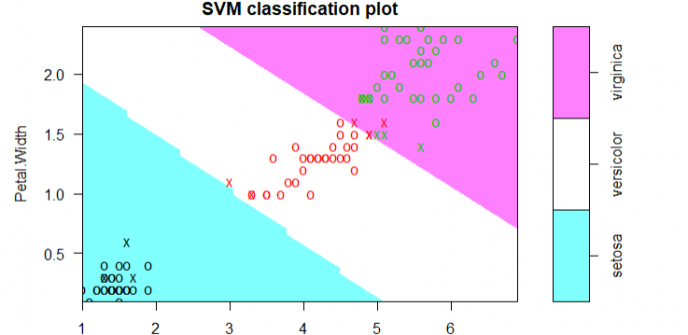
plot(model, train_data, Petal.Width ~ Petal.Length, slice = list(Sepal.Width = 3,Sepal.Length = 4))
从混淆矩阵可以看出我们在训练集上错误2个,可视化展示:
# 测试集测试
pred <- predict(model, test_data)
# 生成混淆矩阵
table(pred, test_data$Species)
# 计算决策值和相应概率
pred <- predict(model, test_data, decision.values = TRUE)
#versicolor/setosa versicolor/virginica setosa/virginica
#98 2.2324532 1.8887801 -0.701372980
#59 2.5993675 1.5101182 -0.918196976
#92 2.3885070 1.2658770 -0.761766669
#71 2.7216550 -0.0795258 -0.894404661
#20 -1.5364814 10.6935445 1.262354439
#10 -1.4255800 10.1798573 1.200091963
#19 -1.1169863 10.4882673 0.999585052
# 我们看第一行,2.2324532正数所以给类别versicolor投票, 1.8887801 为正数所以还是给
# 类别versicolor投票, -0.701372980为负数所以给类别virginica投票。 类别versicolor
# 有两票,所以最终预测为类别versicolor。剩下的以此类推。
attr(pred, "decision.values")[1:4, ]
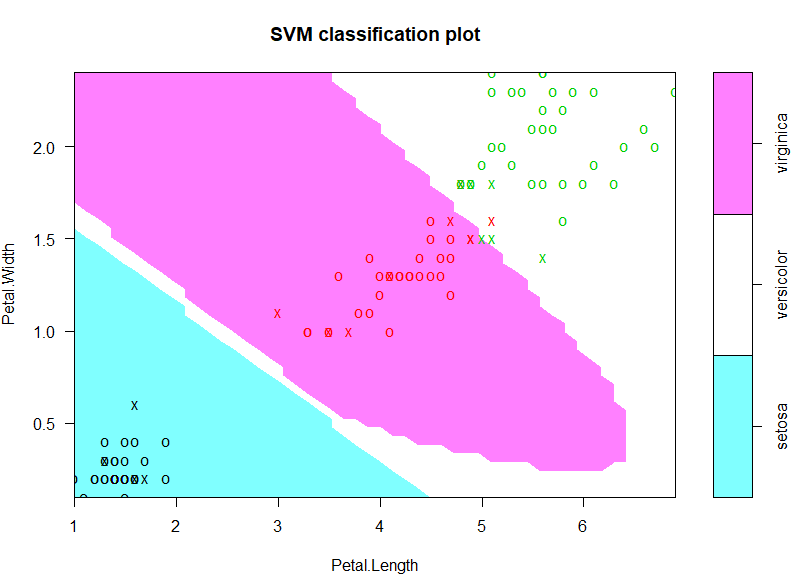
# 可视化展示
plot(model, test_data, Petal.Width ~Petal.Length, slice = list(Sepal.Width = 3,Sepal.Length = 4))
注:个人感觉在plot.svm在多分类(分类数大于二)绘图上略有偏差,大家看图时以理解运用基本原理为主,更多细节可以参考官方文档。
考资料:
1.https://www.rdocumentation.org/packages/e1071/versions/1.7-3/topics/svm
