
近年,大模型是话题的中心。chatGPT以其强大语言处理能力频繁出现在大家的视野中,大模型可以做什么?大模型可以写代码、聊天、办公自动化、写小作文、语言转图片、图片扩展、生成视频等等。
前段时间由于个人原因,博客停更半年,今天我们继续以当下大模型聊聊。对于大部分时间我们只需要花0.000很多个01美刀即可体验像ChatGPT的语言模型功能,但是由于ChatGPT是商业软件并非开源,对于折腾党来说除了去逗GPT开心玩少了很多乐趣。
今天要较介绍的平台GPT4ALL(Open-source large language models that run locally on your CPU and nearly any GPU),是nomic-ai开源的一款可以在本地电脑上跑大模型的一个框架。同时GPT4ALL使用了gguf格式作为模型的标准格式,极大的降低了对电脑的要求和把玩成本。
什么是gguf呢? gguf是开发者 Georgi Gerganov 基于 Llama 模型写的纯 C/C++ 版本,它最大的优势是可以在 CPU上快速地进行推理而不需要 GPU,支持量化模型在CPU中执行推断,从而实现低资源部署LLM。 所以我们可以hugging face仓库中下载很多优质的模型来进行测试学习。
提供了不同平台的安装方法:
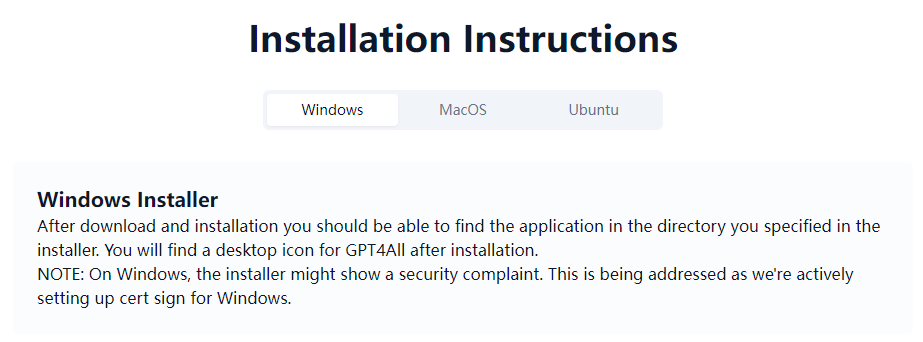
Windows:https://gpt4all.io/installers/gpt4all-installer-win64.exe
Mac:https://gpt4all.io/installers/gpt4all-installer-darwin.dmg
Ubuntu:https://gpt4all.io/installers/gpt4all-installer-linux.run
1)它可以进行Q&A

2)也可以作为个人写作助理
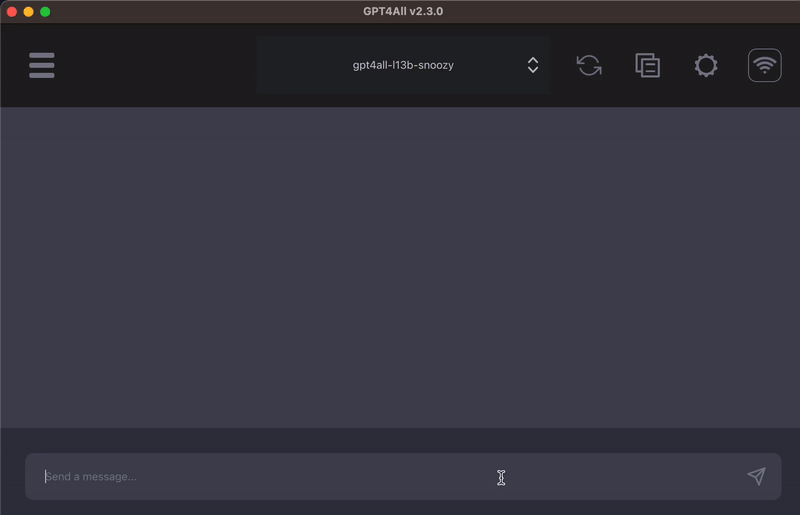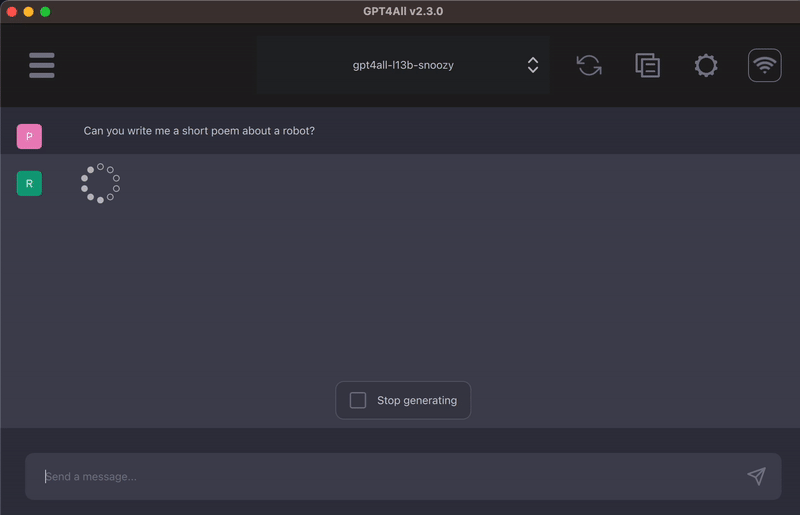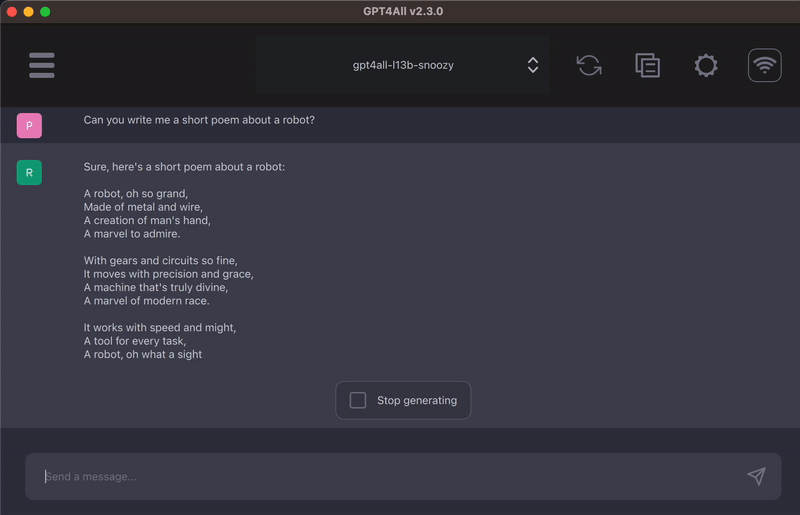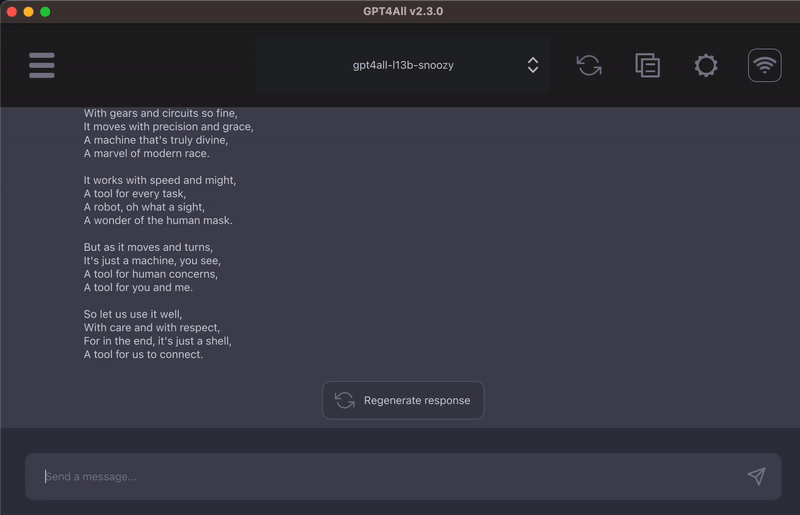
3)可以进行代码的写作

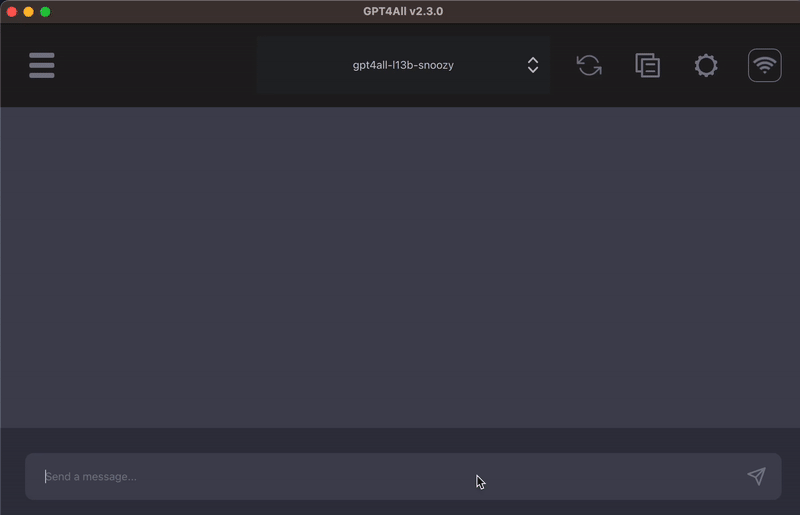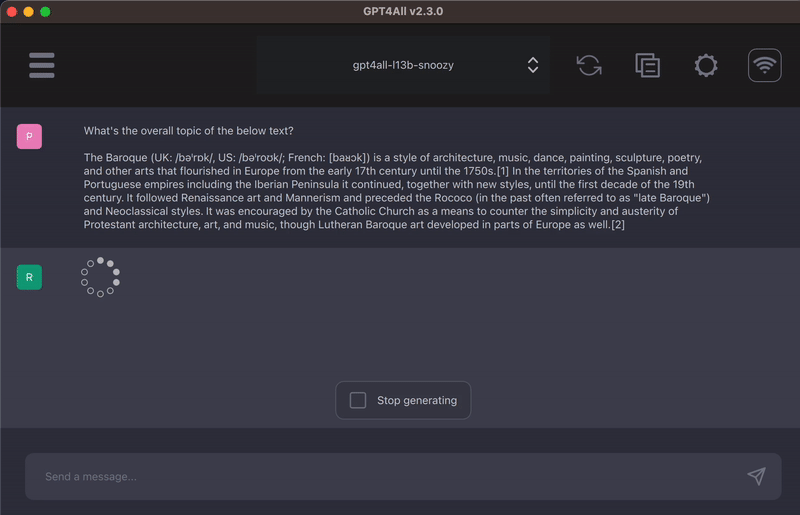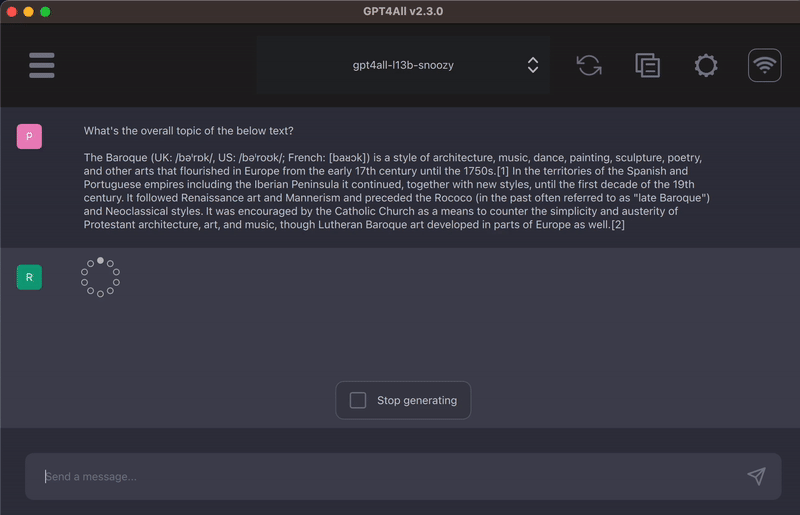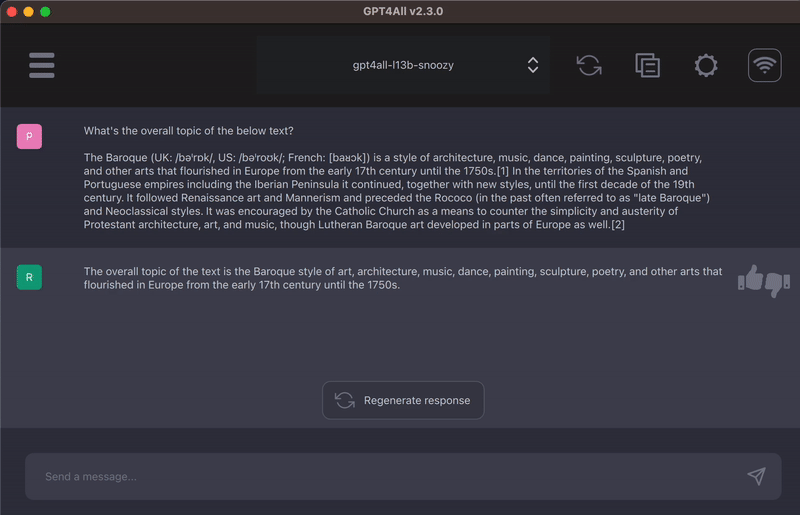
4)可以理解和提取摘要
部分开源模型的性能评估如下:
| Model | BoolQ | PIQA | HellaSwag | WinoGrande | ARC-e | ARC-c | OBQA | Avg |
|---|---|---|---|---|---|---|---|---|
| GPT4All-J 6B v1.0 | 73.4 | 74.8 | 63.4 | 64.7 | 54.9 | 36 | 40.2 | 58.2 |
| GPT4All-J v1.1-breezy | 74 | 75.1 | 63.2 | 63.6 | 55.4 | 34.9 | 38.4 | 57.8 |
| GPT4All-J v1.2-jazzy | 74.8 | 74.9 | 63.6 | 63.8 | 56.6 | 35.3 | 41 | 58.6 |
| GPT4All-J v1.3-groovy | 73.6 | 74.3 | 63.8 | 63.5 | 57.7 | 35 | 38.8 | 58.1 |
| GPT4All-J Lora 6B | 68.6 | 75.8 | 66.2 | 63.5 | 56.4 | 35.7 | 40.2 | 58.1 |
| GPT4All LLaMa Lora 7B | 73.1 | 77.6 | 72.1 | 67.8 | 51.1 | 40.4 | 40.2 | 60.3 |
| GPT4All 13B snoozy | 83.3 | 79.2 | 75 | 71.3 | 60.9 | 44.2 | 43.4 | 65.3 |
| GPT4All Falcon | 77.6 | 79.8 | 74.9 | 70.1 | 67.9 | 43.4 | 42.6 | 65.2 |
| Nous-Hermes | 79.5 | 78.9 | 80 | 71.9 | 74.2 | 50.9 | 46.4 | 68.8 |
| Nous-Hermes2 | 83.9 | 80.7 | 80.1 | 71.3 | 75.7 | 52.1 | 46.2 | 70.0 |
| Nous-Puffin | 81.5 | 80.7 | 80.4 | 72.5 | 77.6 | 50.7 | 45.6 | 69.9 |
| Dolly 6B | 68.8 | 77.3 | 67.6 | 63.9 | 62.9 | 38.7 | 41.2 | 60.1 |
| Dolly 12B | 56.7 | 75.4 | 71 | 62.2 | 64.6 | 38.5 | 40.4 | 58.4 |
| Alpaca 7B | 73.9 | 77.2 | 73.9 | 66.1 | 59.8 | 43.3 | 43.4 | 62.5 |
| Alpaca Lora 7B | 74.3 | 79.3 | 74 | 68.8 | 56.6 | 43.9 | 42.6 | 62.8 |
| GPT-J 6.7B | 65.4 | 76.2 | 66.2 | 64.1 | 62.2 | 36.6 | 38.2 | 58.4 |
| LLama 7B | 73.1 | 77.4 | 73 | 66.9 | 52.5 | 41.4 | 42.4 | 61.0 |
| LLama 13B | 68.5 | 79.1 | 76.2 | 70.1 | 60 | 44.6 | 42.2 | 63.0 |
| Pythia 6.7B | 63.5 | 76.3 | 64 | 61.1 | 61.3 | 35.2 | 37.2 | 56.9 |
| Pythia 12B | 67.7 | 76.6 | 67.3 | 63.8 | 63.9 | 34.8 | 38 | 58.9 |
| Fastchat T5 | 81.5 | 64.6 | 46.3 | 61.8 | 49.3 | 33.3 | 39.4 | 53.7 |
| Fastchat Vicuña 7B | 76.6 | 77.2 | 70.7 | 67.3 | 53.5 | 41.2 | 40.8 | 61.0 |
| Fastchat Vicuña 13B | 81.5 | 76.8 | 73.3 | 66.7 | 57.4 | 42.7 | 43.6 | 63.1 |
| StableVicuña RLHF | 82.3 | 78.6 | 74.1 | 70.9 | 61 | 43.5 | 44.4 | 65.0 |
| StableLM Tuned | 62.5 | 71.2 | 53.6 | 54.8 | 52.4 | 31.1 | 33.4 | 51.3 |
| StableLM Base | 60.1 | 67.4 | 41.2 | 50.1 | 44.9 | 27 | 32 | 46.1 |
| Koala 13B | 76.5 | 77.9 | 72.6 | 68.8 | 54.3 | 41 | 42.8 | 62.0 |
| Open Assistant Pythia 12B | 67.9 | 78 | 68.1 | 65 | 64.2 | 40.4 | 43.2 | 61.0 |
| Mosaic MPT7B | 74.8 | 79.3 | 76.3 | 68.6 | 70 | 42.2 | 42.6 | 64.8 |
| Mosaic mpt-instruct | 74.3 | 80.4 | 77.2 | 67.8 | 72.2 | 44.6 | 43 | 65.6 |
| Mosaic mpt-chat | 77.1 | 78.2 | 74.5 | 67.5 | 69.4 | 43.3 | 44.2 | 64.9 |
| Wizard 7B | 78.4 | 77.2 | 69.9 | 66.5 | 56.8 | 40.5 | 42.6 | 61.7 |
| Wizard 7B Uncensored | 77.7 | 74.2 | 68 | 65.2 | 53.5 | 38.7 | 41.6 | 59.8 |
| Wizard 13B Uncensored | 78.4 | 75.5 | 72.1 | 69.5 | 57.5 | 40.4 | 44 | 62.5 |
| GPT4-x-Vicuna-13b | 81.3 | 75 | 75.2 | 65 | 58.7 | 43.9 | 43.6 | 63.2 |
| Falcon 7b | 73.6 | 80.7 | 76.3 | 67.3 | 71 | 43.3 | 44.4 | 65.2 |
| Falcon 7b instruct | 70.9 | 78.6 | 69.8 | 66.7 | 67.9 | 42.7 | 41.2 | 62.5 |
| text-davinci-003 | 88.1 | 83.8 | 83.4 | 75.8 | 83.9 | 63.9 | 51 | 75.7 |
官方也提供了多个模型的下载:
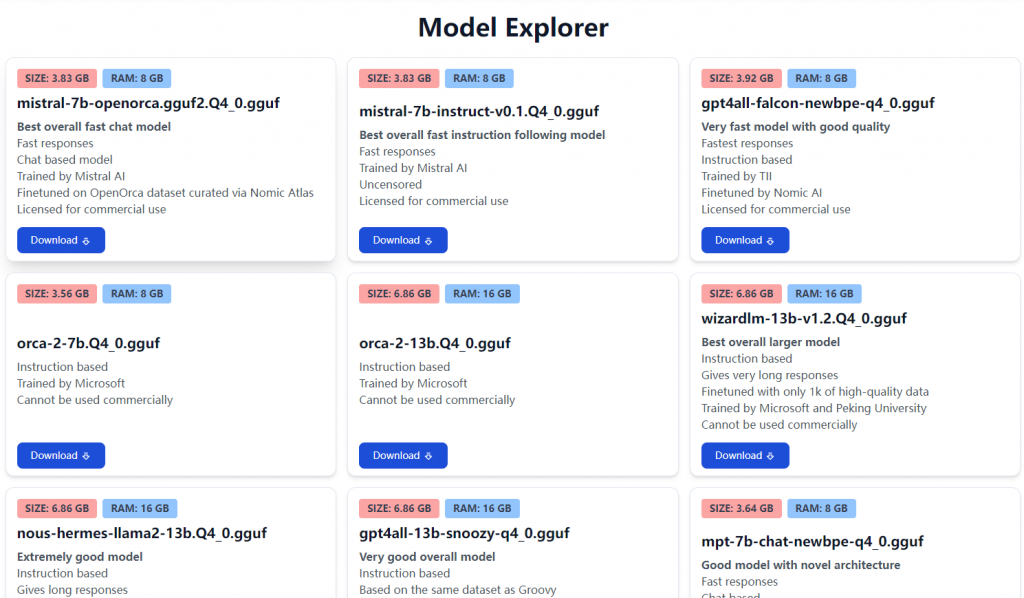
上面是开箱即用的安装方式,只要下载好模型和安装包进行安装就可以使用了。
我们也可以使用python版的自己来定制,首先通过pip安装:
pip install gpt4all安装完成后,下面官方推荐的模型进行测试:
from gpt4all import GPT4All
model = GPT4All("orca-mini-3b-gguf2-q4_0.gguf")
output = model.generate("The capital of France is ", max_tokens=3)
print(output)如果有好的显卡支持可以用下面方式调用:
from gpt4all import GPT4All
model = GPT4All("orca-mini-3b-gguf2-q4_0.gguf", device='gpu') # device='amd', device='intel'
output = model.generate("The capital of France is ", max_tokens=3)
print(output)测试后总体感觉不错,对于问答和名词解释相当准确,聊天方面相对chatGPT还是有一段距离,不过对于学习和DIY是足够了。
参考资料:
1.https://github.com/nomic-ai/gpt4all
2.https://gpt4all.io/index.html
