
DAVID是一个综合的生物信息数据库,其整合了生物学数据和分析工具,为大规模的基因或蛋白列表(成百上千个基因ID或者蛋白ID列表)提供系统综合的生物功能注释信息,帮助研究人员从中提取生物学相关信息。

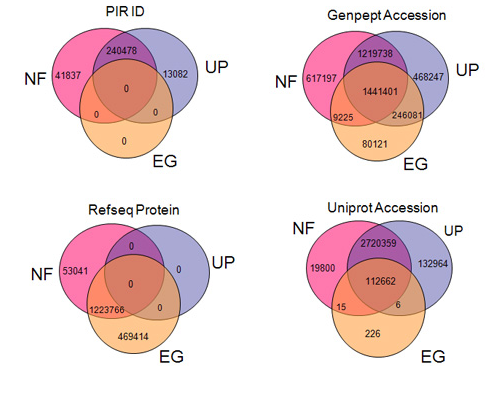
由于生物研究的复杂性和分布式特性,目前的生物数据库的注释信息分布在许多由独立团体维护的冗余数据库中,如 GenBank Accession;基因 ID;RefSeq ;PIR;UniProt ID;UniProt Accession ;Affymetrix 探针 ID;等等。整合这些数据的主要挑战来自不同功能注释数据库使用的不同类型基因标识符的交叉引用(如下图展示了不同类型蛋白质标识ID的覆盖和重叠情况 )。
DAVID通过聚合各个数据库信息来整合,如下图所示通过单连锁算法构建的DAVID基因知识库
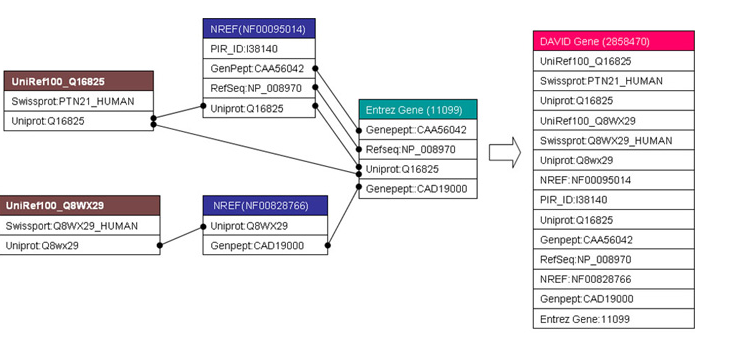
其中构建 DAVID基因知识库数据联合运用了各大相关的参考资源数据库:
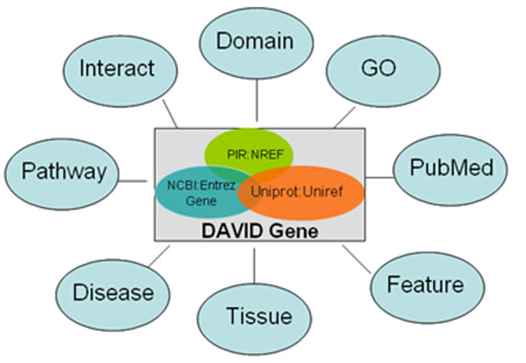
DAVID 知识库中涉及到很多ID的整合:

DAVID知识库覆盖的数据库资源如下:
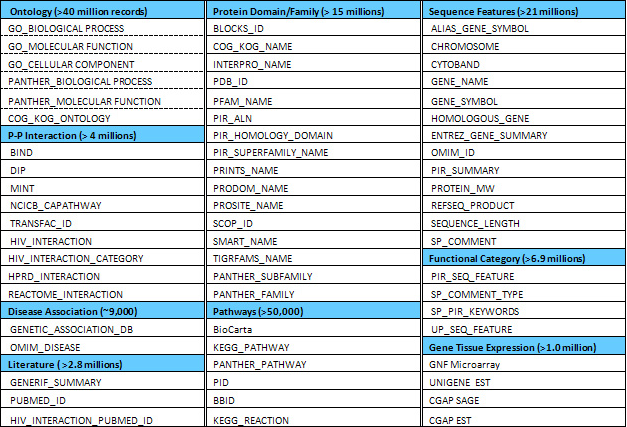
DAVID注释方式:
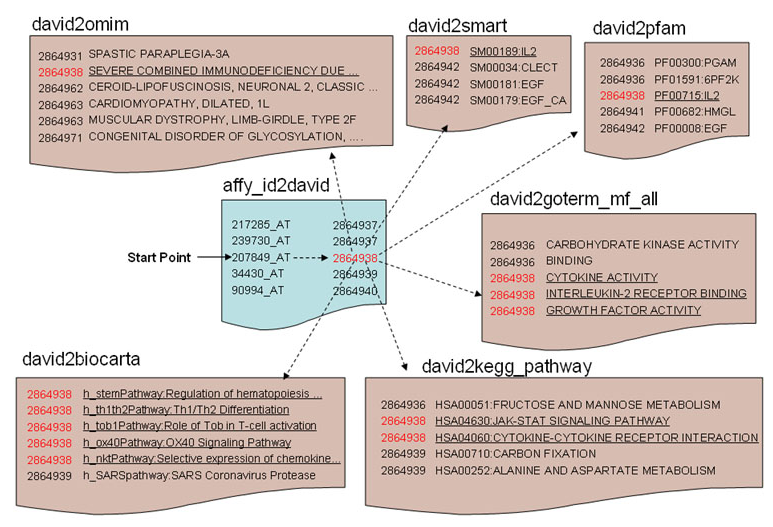
DAVID提供了强大的数据注释、富集分析等功能,同时也提供了在线Web可视化操作界面,一直以来被生命科学邻域研究者广泛引用。
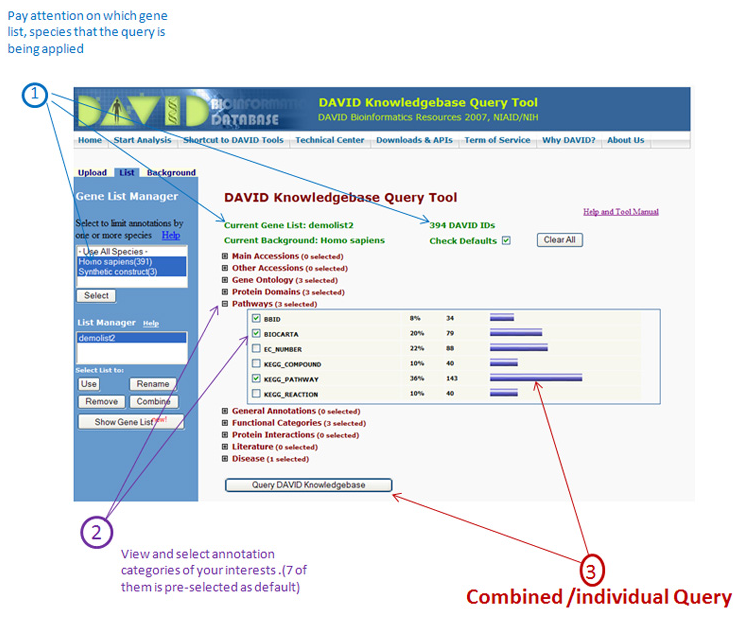
曾经因为数据库长久不更新引来很多人的吐槽,但是时隔十年后最新的版本对数据库进行了整体的更新和改进,总体来说是一个很棒的研究工具。
参考资料:
1.https://david.abcc.ncifcrf.gov/helps/knowledgebase/DAVID_gene.html#coverage
