
一般我们经常会遇见一种情况:把一个pdf里面的表格需要整理到excel,很多人可能会想到用ABBYY等软件,但是如果是企业用就要小心了,目前市面上的大部分软件是商用收费的,但是我们也可以用开源的软件来试先这个过程,比如: Pdfplumber!
Pdfplumber是一个可以处理pdf文件的python库,可以查找文本字符、矩阵、和行的详细信息,也可以对表格进行提取等操作,非常方便。
安装:pip install pdfplumber
安装完成后在终端输入:pdfplumber --help可以产看帮助信息
使用说明: pdfplumber [-h] [--format {csv,json}]
[--types {char,rect,line,curve,image,annot} [{char,rect,line,curve,image,annot} ...]]
[--pages PAGES [PAGES ...]] [--indent INDENT]
[infile]
必要参数:
infile
可选参数:
-h, --help 显示帮助信息
--format {csv,json} csv or json,json格式返回更多信息; 它包含PDF级别的元数据(metadata)和每个页面的高度/宽度信息。
--types {char,rect,line,curve,image,annot} [{char,rect,line,curve,image,annot} ...]
--pages PAGES [PAGES ...] 一个以空格分隔,以1索引开头的页面或带连字符的页面范围的列表。
--indent INDENT JSON美化标准下面用一个示例演示表格提取:
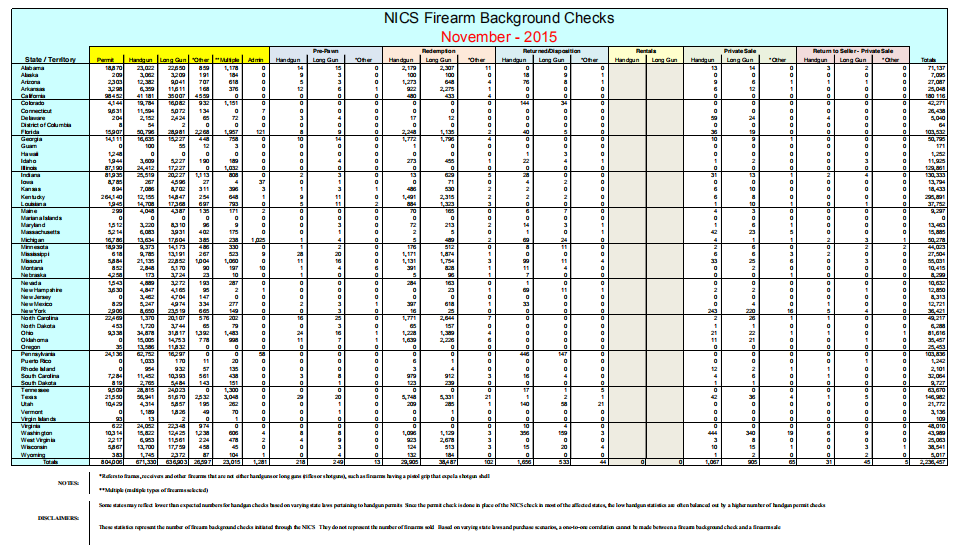
# 简单的示例
import pdfplumber
import pandas as pd
with pdfplumber.open("background-checks.pdf") as pdf:
# 提取第一页文字信息
page = pdf.pages[0]
text = page.extract_text()
print(text)
# 提取第一页表格信息
table = page.extract_tables()
for t in table:
# 转化成DataFrame
df = pd.DataFrame(t[1:], columns=t[0])
# 将表格输出到csv文件
df.to_csv("background-checks-table.csv")
print(df)
总体来说识别效果还是很好的,表头由于有很多合并列,所以输出csv的时候会有错位。同时 pdfplumber 提供了debug功能,能够获取pdf页面中的表格,可以对其进行调整,以优化识别的情况 ,更多详细可以参考官方github。
参考资料:
1.https://github.com/jsvine/pdfplumber
