
随机森林是一种灵活的、便于使用的机器学习算法,可以用来进行分类和回归任务。之前一篇文章通过R语言详细演示了如何用R做随机森林预测,本文主要通过python向大家介绍如何完成一个基本得随机森林预测。
随机森林的基本原理如下图:
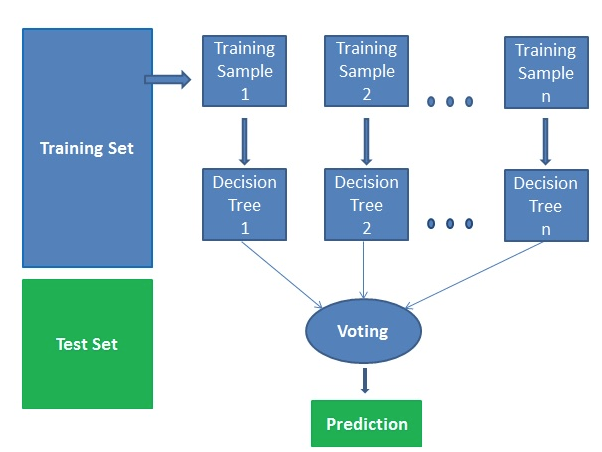
我们主要用到Scikit-learn(sklearn)包,其对常用的机器学习方法进行了封装,包括回归(Regression)、降维(Dimensionality Reduction)、分类(Classfication)、聚类(Clustering)等方法。我们主要用 Scikit-learn 进行随机森林演示:
# 需要用到的模块
from sklearn.ensemble import RandomForestClassifier as RFC
from sklearn.datasets import load_iris
from sklearn import metrics
import numpy as np
import pandas as pd
import seaborn as sn
import matplotlib.pyplot as plt加载鸢尾花数据:
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names) 分训练集和测试集数据
df['is_train'] = np.random.uniform(0, 1, len(df)) <= .75
df['species'] = pd.Categorical.from_codes(iris.target, iris.target_names)
train, test = df[df['is_train']==True], \
df[df['is_train']==False]定义特征列
features = df.columns[0:4]RF建模(RandomForestClassifier函数)
forest = RFC(n_jobs=2,
n_estimators=500, # 在利用最大投票数或平均值来预测之前,建立子树的数量
criterion='gini')
y, _ = pd.factorize(train['species'])
forest.fit(train[features], y)测试集预测
preds = iris.target_names[forest.predict(test[features])]
# 打印混淆矩阵
confusion_matrix = pd.crosstab(index=test['species'],
columns=preds,
rownames=['actual'],
colnames=['preds'])
print(confusion_matrix)preds setosa versicolor virginica
actual
setosa 13 0 0
versicolor 0 13 0
virginica 0 0 12
绘制混淆矩阵热图
sn.heatmap(confusion_matrix, annot=True)
print('Accuracy: ', metrics.accuracy_score(test['species'], preds))
plt.show()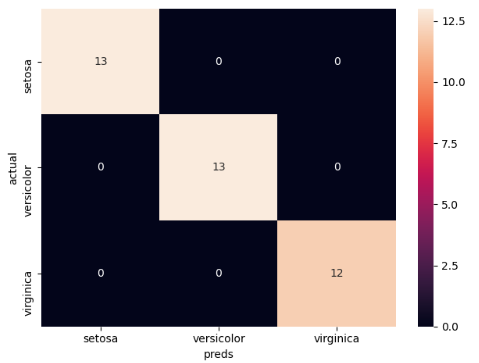
计算变量重要程度
# 计算变量重要程度
importances = forest.feature_importances_
indices = np.argsort(importances)
# 绘制变量重要程度图
plt.figure(1)
plt.title('Feature Importances')
plt.barh(range(len(indices)), importances[indices], color='b', align='center')
plt.yticks(range(len(indices)), features[indices])
plt.xlabel('Relative Importance')
plt.show()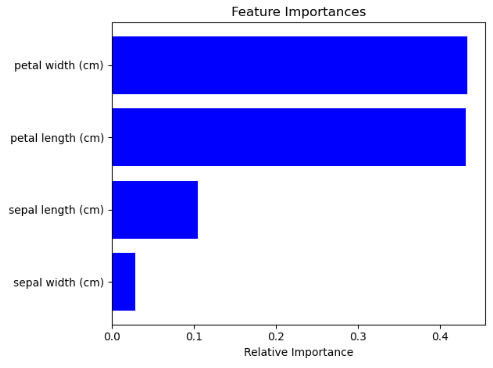
一个简单的随机森林预测模型就完成了。当然,利用随机森林预测也要注意避免数据过拟合,如:加大数据量、交叉验证、不同的测试集验证等。
下面给出本次的完整代码:
from sklearn.ensemble import RandomForestClassifier as RFC
from sklearn.datasets import load_iris
from sklearn import metrics
import numpy as np
import pandas as pd
import seaborn as sn
import matplotlib.pyplot as plt
if __name__ == "__main__":
# 加载鸢尾花数据
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
# 分训练集和测试集数据
df['is_train'] = np.random.uniform(0, 1, len(df)) <= .75
df['species'] = pd.Categorical.from_codes(iris.target, iris.target_names)
train, test = df[df['is_train']==True], \
df[df['is_train']==False]
# 定义特征列
features = df.columns[0:4]
# RF建模
forest = RFC(n_jobs=2,
n_estimators=500,
criterion='gini')
y, _ = pd.factorize(train['species'])
forest.fit(train[features], y)
# 测试集预测
preds = iris.target_names[forest.predict(test[features])]
# 打印混淆矩阵
confusion_matrix = pd.crosstab(index=test['species'],
columns=preds,
rownames=['actual'],
colnames=['preds'])
print(confusion_matrix)
# 绘制混淆矩阵热图
sn.heatmap(confusion_matrix, annot=True)
print('Accuracy: ', metrics.accuracy_score(test['species'], preds))
plt.show()
# 计算变量重要程度
importances = forest.feature_importances_
indices = np.argsort(importances)
# 绘制变量重要程度图
plt.figure(1)
plt.title('Feature Importances')
plt.barh(range(len(indices)), importances[indices], color='b', align='center')
plt.yticks(range(len(indices)), features[indices])
plt.xlabel('Relative Importance')
plt.show()参考资料:
1.https://www.datacamp.com/community/tutorials/random-forests-classifier-python
